Multi-Label Video Classification ¶
A TensorFlow 2.0 Journey, and More! ¶
Kyle Chung
2019-07-25 Last Updated
This is a project I've done in the open project week during my training on Goole's Advanced Solutions Labs at Singapore site. The dataset used is YouTue-8M: a public dataset created by Google Research. It contains pre-processed video features in TensorFlow TFRecord format.
These are the stuff I've done during the week:
- Use TensorFlow to build a baseline model for youtube video label prediction
- Deploy the model onto Google Cloud AI Platform as a prediction service
- Create an asynchronous web appilication that user can input a youtube video share link and get the predicted labels
This notebook is a final wrap-up of the project, with some additional follow-up improvement. It can also serve as a reference point for my experience on TensorFlow 2.0, which is still in its beta stage as write-up of this notebook.
import os
import logging
import numpy as np
import tensorflow as tf
logging.getLogger("tensorflow").setLevel(logging.ERROR)
# Configure array print width.
np.set_printoptions(edgeitems=2)
np.core.arrayprint._line_width = 160
print(tf.__version__)
Deal with TFRecords¶
TFRecords are an efficient way of storing data and performing batch training in TensorFlow modeling. The advatnage is that it can handle virtually any data type, not limited to a tabular representation. Of course it comes at a cost: We do need some extra engineering effort to handle data in tfrecord format.
In this section we'll talk about how to read, create, and process data in tfrecord format.
%%bash
# List some files from youtube-8m video-level training data.
ls -d -l data/video/* | grep "train.*tfrecord$" | head -n3
tfrec_file = "data/video/train0001.tfrecord"
Inspection of TFRecords¶
To inspect a given tfrecord without any schema, it is best to take a single example and print its content in plain text.
Since all kinds of features are serialized to byte strings in tfrecord, the inspection is agnostic to the original feature format.
In TF 2.0 the data handling framework has been unified to the tf.data API.
# Create a dataset iterator of tfrecords.
rec_iter = tf.data.TFRecordDataset(tfrec_file)
# Take just one example.
# The return object is a Tensor of a single byte string.
rec_ex = next(rec_iter.__iter__())
# To parse it we'd like to get rid of the Tensor wrapping,
# leaving the byte string alone.
rec_ex = rec_ex.numpy()
example = tf.train.Example() # For sequence examples use tf.train.SequenceExample.
example.ParseFromString(rec_ex)
# The parsed result will be a human-readable protobuf.
print(str(example)[:500]) # Truncated to print less.
Parse TFRecords with Schema¶
To really make use of data stored in tfrecords, we need to specify a schema to parse the underlying protobuf.
We use tf.io.FixedLenFeature and tf.io.VarLenFeature to specify the nature of the features to be parsed, including its length, type, and dimension.
# Specify feature spec.
video_feature_spec = {
"id": tf.io.FixedLenFeature([], tf.string),
"labels": tf.io.VarLenFeature(tf.int64),
"mean_rgb": tf.io.FixedLenFeature((1024,), tf.float32),
"mean_audio": tf.io.FixedLenFeature((128,), tf.float32)
}
# Take another example in the tfrecords.
rec_ex = next(rec_iter.__iter__())
# Parse with feature spec.
# To parse multiple examples as a batch, use tf.io.parse_example instead.
parsed_example = tf.io.parse_single_example(rec_ex, features=video_feature_spec)
# The result is a dict of feature Tensors.
tf.print(parsed_example)
Making Input Function for Modeling¶
For training using custom tf.estimator.Estimator we need a so-called input function to handle the data pipeline.
An input function takes the source files, convert records into tf.data.Dataset and apply necessary transofrmation.
Conventionally the resulting dataset will return a tuple of features and labels, where the features are warpped in a dict of tensors and labels are purely a tensor.
This time we will use Feature Column to define our features, the corresponding feature spec can be derived from feature columns.
One special treatment is required to encode the label tensor. Since the task is a multi-label classification, meaning that each example can have more than one correct labels, we need to transform the label tensor into a dense multi-hot encoding representation in order to perform loss calculation.
from tensorflow import feature_column as fc
# Define feature columns.
# We will ignore the id column since we don't need it.
feat_col_video = [
fc.numeric_column(key="mean_rgb", shape=(1024,), dtype=tf.float32),
fc.numeric_column(key="mean_audio", shape=(128,), dtype=tf.float32),
fc.indicator_column(fc.categorical_column_with_identity(
key="labels", num_buckets=3862))
]
# Derive feature spec from feature columns.
feat_spec_video = fc.make_parse_example_spec(feat_col_video)
tf.print(feat_spec_video)
from functools import partial
multi_hot_encoder = tf.keras.layers.DenseFeatures(feat_col_video[-1])
def _parse(examples, spec, batch_size, n_class, multi_hot_y):
features = tf.io.parse_example(examples, features=spec)
labels = features.pop("labels")
if multi_hot_y:
labels = multi_hot_encoder({"labels": labels})
return features, labels
def input_fn(infiles, spec, batch_size, n_class, multi_hot_y=True, mode=tf.estimator.ModeKeys.TRAIN):
dataset = tf.data.TFRecordDataset(tf.io.gfile.glob(infiles))
if mode == tf.estimator.ModeKeys.TRAIN:
dataset = dataset.shuffle(buffer_size=1000).repeat(count=None)
dataset = dataset.batch(batch_size, drop_remainder=True)
else:
dataset = dataset.batch(batch_size, drop_remainder=False)
dataset = dataset.map(partial(_parse, spec=spec, batch_size=batch_size,
n_class=n_class, multi_hot_y=multi_hot_y),
num_parallel_calls=4)
dataset = dataset.prefetch(batch_size)
return dataset
# Test the input function.
train_files = "data/video/train*"
dataset = input_fn(train_files, spec=feat_spec_video, batch_size=32, n_class=3862)
# Dataset is iterable.
for x, y in dataset:
print("======Feature Dict======")
print(x)
print("======Label Tensor:======")
print(y)
break
If we don't do multi-hot dense encoding, the resulting label tensor will be a sparse tensor recording the label indices with variable length. We can print also its dense representation for a clear view:
dataset_test = input_fn(train_files, spec=feat_spec_video,
batch_size=32, n_class=3862, multi_hot_y=False)
for x_test, y_test in dataset_test:
break
print(tf.sparse.to_dense(y_test)[:5])
Write TFRecords¶
In this project we don't really need to write TFRecords. Since the only operation needed when doing model inference is covered by the starter code's feature extraction script.
For details about writing TFRecords one can refer to the official document.
Debug Network Layers¶
We will use tf.keras.layers functional API to construct our model.
Before we build the model, it is good to first observe how feature columns are parsed into network layers.
We can use tf.keras.layers.DenseFeatures to create a layer from a list of feature columns.
Essentially what it does is just to concatenate the vector to form a single tensor ready for connection to subsequent hidden layers.
Feed Forward¶
# Specify feature columns that only contains features but not labels.
xname = ["mean_rgb", "mean_audio"]
feat_col_x = [col for col in feat_col_video if col.name in xname]
# Create a layer out of feature columns.
input_layer = tf.keras.layers.DenseFeatures(feat_col_x)
# Feed the layer with one batch of features.
print(input_layer(x))
Let's create a final output layer to have number of neurons equal to number of classes, which is 3862 in this dataset. And we feed the input layer derived from feature columns to this output layer to arrive the model output.
final_layer = tf.keras.layers.Dense(3862, activation="sigmoid")
# Feed-forward.
logits = input_layer(x)
output = final_layer(logits)
# The network output.
print(output)
To verify what's going on here, we can extract the initialized weights and biases from the final layer.
The output should be nothing more than just a sigmoid applying on a dot product of the input and final layer.
Sp if we manually implement the matrix operation, the result shoudl coincide with that of using tf.keras.layers.
# By default the bias is zero-initialized,
# so it won't affect our comparison before the model start to learn.
weights, biases = final_layer.get_weights()
output_check = tf.sigmoid(tf.matmul(logits, weights) + biases)
print(output_check)
Loss¶
Now we have our output we can calculate the loss comparing to the label.
There are lots of high level API for loss calculation in the tf.keras.losses module.
Let's examine the API for binary cross entropy.
bce = tf.keras.losses.BinaryCrossentropy(from_logits=False)
print(bce(y, output).numpy())
The cross entropy is defined as:
$$ \mbox{Cross Entropy Loss} = - \sum_{i=1}^N y_i\ln(q_i) + (1 - y_i)\ln(1 - q_i), $$where $q_i$ is the model predicted probability for the $i$-th example.
For multi-label case the API simply apply the calculation across both batch and label dimension. That is, the summation is over both number of examples and number of labels. To verify the result, we can manually code the calculation:
# This is not numerically stable but we don't mind for a quick dirty check.
z = y * tf.math.log(output) + (1 - y) * tf.math.log(1 - output)
print(tf.reduce_mean(-z).numpy())
The resulting number won't be exactly the same due to smoothing done by default in the API to avoid numerical instability.
We can also use a lower level API from the tf.keras.backend module to gain more control on how we'd like to aggregate individual losses.
For example, we may want to calculate instead the Hamming Loss which suits more for a multi-label scenario.
Essentially we are still calculating individual cross entropy, but will sum over the label dimension first, then do the averagging to arrive the final loss value.
# Retain batch_size x n_class dimension.
losses = tf.keras.backend.binary_crossentropy(y, output, from_logits=False)
hamming_loss = tf.reduce_mean(tf.reduce_sum(-z, axis=1))
print(hamming_loss.numpy())
Evaluation Metrics¶
Evaluation metric is usually different from loss. The former is used to guide the model in how weights should be updated, while the latter is the final criteria to judge the performance of a trained model. (Of course the ideal case is to align the two but for practical reason this is not always doable.)
The tf.keras.metrics module contains lots of built-in classifcal evaluation metrics at our disposal.
To calculate the metric given a batch:
# Use precision as an example.
# The result is really bad since we haven't started to train the model.
# All weights are just randomly initialized.
m = tf.keras.metrics.Precision()
m.update_state(y_true=y, y_pred=output)
m.result().numpy()
tf.keras.metrics.Metric is special in that it is stateful, so can be used to update the metric by batch.
This fits well with the batching data pipeline adopted by the tensorflow neural network learning framework.
Build Models¶
For model not very complicated and customized, tf.keras.models API is a very fast but also flexible way for prototyping.
We will simply connect the input layer to output layer, essentially build K-logistic regression model for K labels independently.
This is a classical baseline model for a multi-label learning task.
train_files = "data/video/train*"
valid_files = "data/video/valid*"
train_dataset = input_fn(train_files, spec=feat_spec_video,
batch_size=1024, n_class=3862)
valid_dataset = input_fn(valid_files, spec=feat_spec_video,
batch_size=1024, n_class=3862,
mode=tf.estimator.ModeKeys.EVAL)
l2_reg = tf.keras.regularizers.l2(1e-8)
model = tf.keras.models.Sequential(name="baseline")
model.add(tf.keras.layers.DenseFeatures(feat_col_x, name="input"))
model.add(tf.keras.layers.Dense(3862, activation="sigmoid", name="output",
kernel_regularizer=l2_reg))
model.compile(
optimizer="adam",
loss="binary_crossentropy",
metrics=[
tf.keras.metrics.Precision(),
tf.keras.metrics.Recall()
]
)
To summarize the network architecture we can train a dummy step in order for the model to figure out the input dimension (since we don't bother define them in advance).
model.fit(dataset, epochs=1, steps_per_epoch=1, verbose=0)
model.summary()
# Test with more steps, also with validation.
model.fit(dataset, validation_data=valid_dataset, epochs=1,
steps_per_epoch=100, validation_steps=10)
Use Tensorboard with Keras Model¶
To use tensorboard for keras model on tracking the model loss and evaluation metrics, we need to explicitly implement a callback function and pass it to the fit method.
%%bash
# Create directory to save pre-trained model tb events.
mkdir -p models
tensorboard_callback = tf.keras.callbacks.TensorBoard() # Default to ./logs.
model.fit(dataset, validation_data=valid_dataset, epochs=1,
steps_per_epoch=100, validation_steps=10,
callbacks=[tensorboard_callback],
verbose=0)
Then we can run TensorBoard as usual:
tensorboard --logdir ./logs
Custom Loss Function¶
We'd like to use Hamming Loss, optionally with class weight balancing since the labels are heavily skewed in this dataset. The class weight to fully re-balance the training data distribution for class $i$ is defined as:
$$ \mbox{Class Weight i} = \frac{\mbox{No. of Samples}}{\mbox{No. of Classes} \times \mbox{No. of Class i}} $$import pandas as pd
vocab_file = "data/vocabulary.csv"
def calc_class_weight(infile, scale=1):
"""Calculate class weight to re-balance label distribution.
The class weight for class i (w_i) is determined by:
w_i = total no. samples / (n_class * count(class i))
"""
vocab = pd.read_csv(infile).sort_values("Index")
cnt = vocab["TrainVideoCount"]
w = cnt.sum() / (len(vocab) * cnt)
w = w.values.astype(np.float32)
return pow(w, scale)
class_weights = calc_class_weight(vocab_file, scale=2)
def hamming_loss(y_true, y_pred):
loss = tf.keras.backend.binary_crossentropy(y_true, y_pred, from_logits=False)
return tf.reduce_mean(tf.reduce_sum(loss, axis=1))
def weighted_hamming_loss(y_true, y_pred):
loss = tf.keras.backend.binary_crossentropy(y_true, y_pred, from_logits=False)
loss *= class_weights # By-element product broadcast over rows.
return tf.reduce_mean(tf.reduce_sum(loss, axis=1))
Custom Evaluation Metrics¶
There are two ways to supply custom evaluation metrics for a keras model.
The first approach is to simply pass a function calculating the metric given y_true and y_pred, just similar as what we did for the custom loss function.
This approach, however, has a flaw that it only calculates by-batch metrics.
For a metric that will cumulate the results from multiple batches from the validation dataset,
it is best to implement a stateful metric class as a subclass of tf.keras.metrics.Metric.
For this multi-label task we'd like to imeplemnt a metric to health-check number of predicted classes for our model. It should not tru to predict too many labels on average since the overall average number of labels is only 3.
We will also implement a "Hit@One" metric that calculate how many examples we have the opt predicted class to be a correct prediction.
from tensorflow.python.ops import init_ops
class AverageNClass(tf.keras.metrics.Metric):
def __init__(self, name="average_n_class", **kwargs):
super(tf.keras.metrics.Metric, self).__init__(name=name, **kwargs)
self.n_example = self.add_weight(
"n_example",
shape=(),
dtype=tf.float32,
initializer=init_ops.zeros_initializer)
self.n_predicted_class = self.add_weight(
"n_predicted_class",
shape=(),
dtype=tf.float32,
initializer=init_ops.zeros_initializer)
def update_state(self, y_true, y_pred, **kwargs):
# Accumulate sample size.
batch_size = tf.cast(len(y_true), tf.float32)
self.n_example.assign_add(batch_size)
# Accumulate number of predicted classes.
batch_n_class = tf.reduce_sum(tf.cast(y_pred > .5, tf.float32))
self.n_predicted_class.assign_add(batch_n_class)
def result(self):
return self.n_predicted_class / self.n_example
class HitAtOne(tf.keras.metrics.Metric):
def __init__(self, name="hit_at_one", **kwargs):
super(tf.keras.metrics.Metric, self).__init__(name=name, **kwargs)
self.n_example = self.add_weight(
"n_example",
shape=(),
dtype=tf.float32,
initializer=init_ops.zeros_initializer)
self.hit_at_one = self.add_weight(
"hit_at_one",
shape=(),
dtype=tf.float32,
initializer=init_ops.zeros_initializer)
def update_state(self, y_true, y_pred, **kwargs):
# Accumulate sample size.
batch_size = tf.cast(len(y_true), tf.float32)
self.n_example.assign_add(batch_size)
# Count number of hit@one.
tops = tf.math.argmax(y_pred, axis=1, output_type=tf.int32)
top_idx = tf.stack([tf.range(len(y_true)), tops], axis=1)
hits = tf.gather_nd(y_true, indices=top_idx)
self.hit_at_one.assign_add(tf.reduce_sum(hits))
def result(self):
return self.hit_at_one / self.n_example
def create_baseline_model(name, loss_fn, feat_cols):
l2_reg = tf.keras.regularizers.l2(1e-8)
model = tf.keras.models.Sequential(name="baseline_" + name)
model.add(tf.keras.layers.DenseFeatures(feat_col_x))
model.add(tf.keras.layers.Dense(3862, activation="sigmoid", kernel_regularizer=l2_reg))
model.compile(
optimizer="adam",
loss=loss_fn,
metrics=[
tf.keras.metrics.Precision(),
tf.keras.metrics.Recall(),
AverageNClass(),
HitAtOne()
]
)
return model
Baseline Benchmark¶
Let's benchmark models with different losses.
model_1_dir = os.path.join("models", "loss_experiments", "entropy")
model_1 = create_baseline_model("entropy", loss_fn=tf.keras.losses.binary_crossentropy, feat_cols=feat_col_x)
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=model_1_dir)
model_1.fit(train_dataset, validation_data=valid_dataset,
epochs=5, steps_per_epoch=3000, validation_steps=100,
callbacks=[tensorboard_callback])
model_2_dir = os.path.join("models", "loss_experiments", "hamming")
model_2 = create_baseline_model("hamming", loss_fn=hamming_loss, feat_cols=feat_col_x)
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=model_2_dir)
model_2.fit(train_dataset, validation_data=valid_dataset,
epochs=5, steps_per_epoch=3000, validation_steps=100,
callbacks=[tensorboard_callback])
model_3_dir = os.path.join("models", "loss_experiments", "weighted_hamming")
model_3 = create_baseline_model("weighted_hamming", loss_fn=weighted_hamming_loss, feat_cols=feat_col_x)
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=model_3_dir)
model_3.fit(train_dataset, validation_data=valid_dataset,
epochs=5, steps_per_epoch=3000, validation_steps=100,
callbacks=[tensorboard_callback])
model_test_dir = os.path.join("models", "save_experiments", "ckp", "checkpoint")
cp_callback = tf.keras.callbacks.ModelCheckpoint(
model_test_dir, save_weights_only=True,
load_weights_on_restart=True, verbose=1)
model_test = create_baseline_model("save_test", loss_fn=weighted_hamming_loss, feat_cols=feat_col_x)
model_test.fit(train_dataset, validation_data=valid_dataset,
epochs=1, steps_per_epoch=10, validation_steps=10,
callbacks=[cp_callback], verbose=0)
%%bash
ls -l models/save_experiments/ckp
For large model weights will be sharded; hence there will be a index file to locate the shard for weights.
The load back the weights we will use the tf.keras.Model.load_weights API.
The model must have the same architecture in order to reload the weight-only checkpoint files.
Without using a callback, we can also directly call tf.keras.Model.save_weights method to save the current model weights.
Saving Full Model as SavedModel Directory¶
Using the same approach above we can also choose to store the entire model structure along with the weights by simply setting save_weights_only=False.
The resulting model directory structure will be a little bit different.
The .pb model is a TensorFlow SavedModel object, with its own special internal format.
model_test_dir = os.path.join("models", "save_experiments", "saved_model")
cp_callback = tf.keras.callbacks.ModelCheckpoint(
model_test_dir, save_weights_only=False,
load_weights_on_restart=True, verbose=1)
model_test = create_baseline_model("save_test", loss_fn=weighted_hamming_loss, feat_cols=feat_col_x)
model_test.fit(train_dataset, validation_data=valid_dataset,
epochs=1, steps_per_epoch=10, validation_steps=10,
callbacks=[cp_callback], verbose=0)
%%bash
ls -lR models/save_experiments/saved_model
We can also use tf.keras.Model.save with save_format="tf" to save a model in SavedModel format.
So the following line
model_test.save(os.path.join("models", "save_experiments", "saved_model"), save_format="tf")
will result in exactly the same output model diorectory as in the previous callback function.
Saving Full Model as .h5 File¶
Unlike SavedModel is a directory, we can save the model as one single file.
This can be done by using tf.keras.Model.save with save_format="h5" option:
model_test.save(os.path.join("models", "save_experiments", "saved_model.h5"), save_format="h5")
Model Deployment and Servicing¶
For model deployment we will use gcloud ai-platform command line tool.
We will need to package our code into a simple python modules in order to launch the model training on cloud.
Video Feature Extraction¶
Before we implement the model serving, we need to also imeplement a video processor to extract features from a raw .mp4 file.
This is for us to do model inference on unseen examples.
Let's have a basic walk-through of how the video is processed in the starter code:
import cv2
from app.feature_extractor import feature_extractor
# Reference: https://github.com/google/youtube-8m/tree/master/feature_extractor
# Note that the original module only works for TF 1.x but not 2.0,
# we need to modify the script specifically for tf.GraphDef, tf.Graph, and tf.Session to be
# tf.compat.v1.GraphDef tf.compat.v1.Graph and tf.compat.v1.Session, respectively.
CAP_PROP_POS_MSEC = 0
def frame_iterator(filename, every_ms=1000, max_num_frames=300):
video_capture = cv2.VideoCapture()
if not video_capture.open(filename):
print >> sys.stderr, "Error: Cannot open video file " + filename
return
last_ts = -99999 # The timestamp of last retrieved frame.
num_retrieved = 0
while num_retrieved < max_num_frames:
# Skip frames
while video_capture.get(CAP_PROP_POS_MSEC) < every_ms + last_ts:
if not video_capture.read()[0]:
return
last_ts = video_capture.get(CAP_PROP_POS_MSEC)
has_frames, frame = video_capture.read()
if not has_frames:
break
yield frame
num_retrieved += 1
# Pre-trained ImageNet Inception model and PCA matrices will be downloaded if not found.
extractor = feature_extractor.YouTube8MFeatureExtractor("app/models")
video_file = "data/Dx_fKPBPYUI.mp4" # A test sample.
rgb_features = []
sum_rgb_features = None
fiter = frame_iterator(video_file, every_ms=1000.0)
# Take just one frame.
next(fiter)
rgb = next(fiter)
features = extractor.extract_rgb_frame_features(rgb[:, :, ::-1])
%matplotlib inline
import matplotlib.pyplot as plt
# Plot the extracted frame.
f = plt.imshow(rgb)

# The embeddings generated by the pre-trained Inception model on the above frame.
print(features.shape)
print(features)
Using Google Cloud AI Platform¶
We can package our model as a python module in a way compatible with gcloud ai-platform.
By using gcloud ai-platform as the interface we can easily launch the model training job on Google Cloud for large scale distributed training without any change of our code base.
The following code cells will write necessary python scripts as module, wrapping up all the codes in previous sections together.
Specifically, we need a task.py as the entrypoint for gcloud ai-platform to interface with our module.
If we'd like to use the hyper-parameter tuning service in Google Cloud, we need to make sure the hyper-parameters are part of the task.py command line arguments.
For this project for simplicity we are not going to do that.
%%bash
# Create python module directory.
mkdir -p src
touch src/__init__.py
%%writefile src/eval_metrics.py
"""Custom eval metrics for YouTube-8M model."""
import tensorflow as tf
from tensorflow.python.ops import init_ops
class AverageNClass(tf.keras.metrics.Metric):
def __init__(self, name="average_n_class", **kwargs):
super(tf.keras.metrics.Metric, self).__init__(name=name, **kwargs)
self.n_example = self.add_weight(
"n_example",
shape=(),
dtype=tf.float32,
initializer=init_ops.zeros_initializer)
self.n_predicted_class = self.add_weight(
"n_predicted_class",
shape=(),
dtype=tf.float32,
initializer=init_ops.zeros_initializer)
def update_state(self, y_true, y_pred, **kwargs):
# Accumulate sample size.
batch_size = tf.cast(len(y_true), tf.float32)
self.n_example.assign_add(batch_size)
# Accumulate number of predicted classes.
batch_n_class = tf.reduce_sum(tf.cast(y_pred > .5, tf.float32))
self.n_predicted_class.assign_add(batch_n_class)
def result(self):
return self.n_predicted_class / self.n_example
class HitAtOne(tf.keras.metrics.Metric):
def __init__(self, name="hit_at_one", **kwargs):
super(tf.keras.metrics.Metric, self).__init__(name=name, **kwargs)
self.n_example = self.add_weight(
"n_example",
shape=(),
dtype=tf.float32,
initializer=init_ops.zeros_initializer)
self.hit_at_one = self.add_weight(
"hit_at_one",
shape=(),
dtype=tf.float32,
initializer=init_ops.zeros_initializer)
def update_state(self, y_true, y_pred, **kwargs):
# Accumulate sample size.
batch_size = tf.cast(len(y_true), tf.float32)
self.n_example.assign_add(batch_size)
# Count number of hit@one.
tops = tf.math.argmax(y_pred, axis=1, output_type=tf.int32)
top_idx = tf.stack([tf.range(len(y_true)), tops], axis=1)
hits = tf.gather_nd(y_true, indices=top_idx)
self.hit_at_one.assign_add(tf.reduce_sum(hits))
def result(self):
return self.hit_at_one / self.n_example
%%writefile src/model.py
"""Video classification model on YouTube-8M dataset."""
import os
import logging
from functools import partial
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow import feature_column as fc
from tensorflow.python.lib.io import file_io
from tensorflow.python.ops import init_ops
from .eval_metrics import AverageNClass, HitAtOne
N_CLASS = 3862
BATCH_SIZE = 1024
VOCAB_FILE = "data/vocabulary.csv"
# Exclude audio feature since we didn't implement audio feature extraction.
# Even if the model can be trained on audio feature,
# they won't be available for inference on new video.
FEAT_COL_VIDEO = [
fc.numeric_column(key="mean_rgb", shape=(1024,), dtype=tf.float32),
#fc.numeric_column(key="mean_audio", shape=(128,), dtype=tf.float32),
fc.indicator_column(fc.categorical_column_with_identity(key="labels", num_buckets=N_CLASS))
]
FEAT_X = ["mean_rgb"]
FEAT_SPEC_VIDEO = fc.make_parse_example_spec(FEAT_COL_VIDEO)
MULTI_HOT_ENCODER = tf.keras.layers.DenseFeatures(FEAT_COL_VIDEO[-1])
# If we'd like to use a custom serving input function, we need to use the estimator API.
# There is no document on how a keras model can use a custom serving input function.
KERAS_TO_ESTIMATOR = True
def calc_class_weight(infile, scale=1):
"""Calculate class weight to re-balance label distribution.
The class weight for class i (w_i) is determined by:
w_i = total no. samples / (n_class * count(class i))
"""
if infile.startswith("gs://"):
with file_io.FileIO(infile, "r") as f:
vocab = pd.read_csv(f)
else:
vocab = pd.read_csv(infile)
vocab.sort_values("Index", inplace=True)
cnt = vocab["TrainVideoCount"]
w = cnt.sum() / (len(vocab) * cnt)
w = w.values.astype(np.float32)
return pow(w, scale)
def _parse(examples, spec, batch_size, n_class):
features = tf.io.parse_example(examples, features=spec)
labels = features.pop("labels")
labels = MULTI_HOT_ENCODER({"labels": labels})
return features, labels
def input_fn(infiles, spec, mode=tf.estimator.ModeKeys.TRAIN):
dataset = tf.data.TFRecordDataset(tf.io.gfile.glob(infiles))
if mode == tf.estimator.ModeKeys.TRAIN:
dataset = dataset.shuffle(buffer_size=1000).repeat(count=None).batch(BATCH_SIZE, drop_remainder=True)
else:
dataset = dataset.batch(BATCH_SIZE, drop_remainder=False)
dataset = dataset.map(partial(_parse, spec=spec, batch_size=BATCH_SIZE, n_class=N_CLASS))
dataset = dataset.prefetch(BATCH_SIZE)
return dataset
def serving_input_receiver_fn():
"""Parse seralized tfrecord string for online inference."""
# Accept a list of serialized tfrecord string.
example_bytestring = tf.compat.v1.placeholder(shape=[None], dtype=tf.string)
# Parse them into feature tensors.
features = tf.io.parse_example(example_bytestring, FEAT_SPEC_VIDEO)
features.pop("labels") # Dummy label. Not important at all.
return tf.estimator.export.ServingInputReceiver(features, {"examples_bytes": example_bytestring})
class BaseModel:
def __init__(self, params):
self.params = params
config = tf.estimator.RunConfig(
tf_random_seed=777,
save_checkpoints_steps=max(1000, params["train_steps"] // 10),
model_dir=params["model_dir"]
)
self.class_weights = calc_class_weight(VOCAB_FILE, scale=1)
self.serving_input_receiver_fn = serving_input_receiver_fn
if KERAS_TO_ESTIMATOR:
self.estimator = tf.keras.estimator.model_to_estimator(keras_model=self.model_fn(), config=config)
else:
self.estimator = self.model_fn()
def model_fn(self):
def hamming_loss(y_true, y_pred):
loss = tf.keras.backend.binary_crossentropy(y_true, y_pred, from_logits=False)
if self.params["weighted_loss"]:
loss *= self.class_weights
return tf.reduce_mean(tf.reduce_sum(loss, axis=1))
FEAT_COL_X = [col for col in FEAT_COL_VIDEO if col.name in FEAT_X]
l2_reg = tf.keras.regularizers.l2(1e-8)
if KERAS_TO_ESTIMATOR:
# DenseFeatures doesn't play well with Estimator.
inputs = tf.keras.layers.Input(shape=(1024,), name="mean_rgb")
predictions = tf.keras.layers.Dense(N_CLASS, activation="sigmoid", kernel_regularizer=l2_reg)(inputs)
model = tf.keras.Model(inputs=inputs, outputs=predictions, name="baseline")
else :
model = tf.keras.models.Sequential(name="baseline")
model.add(tf.keras.layers.DenseFeatures(FEAT_COL_X, name="mean_rgb"))
model.add(tf.keras.layers.Dense(N_CLASS, activation="sigmoid", kernel_regularizer=l2_reg))
model.compile(
optimizer="adam",
loss=hamming_loss,
metrics=[
tf.keras.metrics.Precision(),
tf.keras.metrics.Recall(),
AverageNClass(),
HitAtOne()
]
)
return model
def train_and_evaluate(self, params):
if KERAS_TO_ESTIMATOR:
# This is much slower than the native keras model fit under TF 2.0.
train_spec = tf.estimator.TrainSpec(
input_fn=lambda: input_fn(params["train_data_path"], spec=FEAT_SPEC_VIDEO),
max_steps=params["train_steps"]
)
exporter = tf.estimator.FinalExporter(
name="exporter", serving_input_receiver_fn=serving_input_receiver_fn)
eval_spec = tf.estimator.EvalSpec(
input_fn=lambda: input_fn(params["eval_data_path"], spec=FEAT_SPEC_VIDEO,
mode=tf.estimator.ModeKeys.EVAL),
steps=100,
start_delay_secs=60,
throttle_secs=1,
exporters=exporter
)
logging.getLogger("tensorflow").setLevel(logging.INFO)
tf.estimator.train_and_evaluate(
estimator=self.estimator,
train_spec=train_spec,
eval_spec=eval_spec
)
else:
model_dir = os.path.join(".", params["model_dir"])
train_dataset = input_fn(params["train_data_path"], spec=FEAT_SPEC_VIDEO)
valid_dataset = input_fn(params["eval_data_path"], spec=FEAT_SPEC_VIDEO,
mode=tf.estimator.ModeKeys.EVAL)
tb_callback = tf.keras.callbacks.TensorBoard(log_dir=model_dir)
self.estimator.fit(
train_dataset, validation_data=valid_dataset,
epochs=params["train_epochs"], steps_per_epoch=params["train_steps"],
validation_steps=100,
callbacks=[tb_callback])
self.estimator.save(model_dir, save_format="tf")
%%writefile src/task.py
"""Model interface for gcloud ai-platform."""
import argparse
import json
import os
from . import model
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--train_data_path",
help="GCS or local path to training data",
required = True
)
parser.add_argument(
"--train_steps",
help="Steps to run the training job for (default: 1000)",
type=int,
default=1000
)
parser.add_argument(
"--train_epochs",
help="Epochss to run the training job for (default: 1)",
type=int,
default=1
)
parser.add_argument(
"--eval_data_path",
help="GCS or local path to evaluation data",
required= True
)
parser.add_argument(
"--model_dir",
help="GCS location to write checkpoints and export models",
required=True
)
parser.add_argument(
"--weighted_loss",
help = "Use class weights in loss?",
required=False,
default=True
)
parser.add_argument(
"--job-dir",
help="This is not used by our model, but it is required by gcloud",
)
args = parser.parse_args().__dict__
# Append trial_id to path so trials don"t overwrite each other
args["model_dir"] = os.path.join(
args["model_dir"],
json.loads(
os.environ.get("TF_CONFIG", "{}")
).get("task", {}).get("trial", "")
)
# Run the training job
yt8m_model = model.BaseModel(args)
yt8m_model.train_and_evaluate(args)
After we modualize our model, a local trainning job can be triggered by using gcloud ai-platform command line:
For example:
rm -r local_debug_model
gcloud ai-platform local train \
--package-path=src \
--module-name=src.task \
-- \
--train_data_path=data/video/train* \
--eval_data_path=data/video/valid* \
--train_steps=3000 \
--train_epochs=10 \
--model_dir=models/baseline
To train the model on cloud, we can upload the training data to GCS then run instead something like:
gcloud ai-platform jobs submit training yt8m_$(date -u +%y%m%d_%H%M%S) \
--package-path=src \
--module-name=src.task \
--job-dir=gs://${BUCKET}/yt8m \
--python-version=3.5 \
--runtime-version=${TFVERSION} \
--region=us-central1 \
-- \
--train_data_path=gs://${BUCKET}/yt8m/data/video/train* \
--eval_data_path=gs://${BUCKET}/yt8m/data/video/valid* \
--train_steps=30000 \
--output_dir=gs://${BUCKET}/yt8m/models
The followings are tensorboard scalar tracing plots for our local training job.
Training Loss:

Eval Loss:

Eval Precision:

Eval Recall:

Eval Hit@One:

Eval Average Number of Predicted Classes:

AI Platform Prediction Service¶
To deploy a pre-trained model we first need to upload the model directory to GCS. This can be done by for example:
MODEL_DIR="models/baseline"
gsutil -m rm -rf gs://${BUCKET}/yt8m/models
gsutil -m cp -r ${MODEL_DIR} gs://${BUCKET}/yt8m/models
Then to create a model for online prediction:
VERSION="v1"
TFVERSION="1.14"
MODEL_NAME="yt8m_video"
MODEL_DIR=local_debug_model
# Create ai-platform cloud model.
gcloud ai-platform models create ${MODEL_NAME} --regions us-central1
# Remove previous version.
gcloud ai-platform versions delete ${VERSION} --model ${MODEL_NAME} --quiet
# Deploy.
gcloud ai-platform versions create ${VERSION} --model ${MODEL_NAME} \
--origin $(gsutil ls gs://${BUCKET}/yt8m/models/export/exporter | tail -1) \
--python-version=3.5 \
--runtime-version ${TFVERSION}
Note that as of now (July 2019) AI Platform runtime doesn't support TF 2.0 yet. But our code is backward-compatible with 1.14.
Online Prediction with a Wep App¶
We develop a web service using Flask to receive user request about a YouTube video share link for online label(s) prediction.
Also we will use socket.io to implement asynchronous processing to improve user experience. (It takes time to process a raw video without using a dedicated server.)
Also we will use youtube-dl as the YouTube video downloader to download the requested video in .mp4 format.
For video feature extraction we directly utilize the open source starter code from Google Research.
The overall architecture of our application will look like this:

To simplify things (in a one-week window) the web server is also doing video feature extraction which is a heavy task since it involves in loading a pre-trained Inception model and making inference through the graph.
The ideal architecture should be something like:

%%bash
# Create directories for our flask app.
mkdir -p app
mkdir -p app/templates
mkdir -p app/static
mkdir -p app/assets
Server-Side Coding¶
The web server needs to do a series of task given a user request:
- Download the requested video
- Process the video to extract features in tfrecord
- Parse the tfrecord back and package it in base64, send it to the online predictor
- Receive prediction result and tidy it up, then send it to the front-end
Ideally we should by-pass the writing of tfrecord and direectly package the serialized string in-memory. But since we utilize the starter code in feature extractor without changing anything, this is the extra effort needed to be done.
Here is the main script for the server:
%%writefile app/main.py
"""Run Flask app for YouTube-8M model demo."""
import os
import sys
import shutil
import tempfile
import subprocess
import base64
from flask import Flask, render_template, request
from flask_socketio import SocketIO, emit
import googleapiclient.discovery
import tensorflow as tf
import numpy as np
app = Flask(__name__)
socketio = SocketIO(app)
PROJECT = os.environ["PROJECT"] # Name of gcloud project.
MODEL = "yt8m_video" # Name of the deployed ai-platform model.
LABEL_VOCAB_FILE = "../data/vocabulary.csv"
VIDEO_DIR = "test_videos"
TFREC_DIR = "test_tfrecords"
YT_DL = "bin/youtube-dl"
FT_EXTRACTOR = "feature_extractor/extract_tfrecords_main.py"
def read_label_vocab(infile=LABEL_VOCAB_FILE):
with open(infile, "rt") as f:
raw_vocab = [l.strip("\n") for l in f.readlines()]
header = raw_vocab[0].split(",")
index_pos = header.index("Index")
label_pos = header.index("Name")
vocab = {}
for line in raw_vocab[1:]:
line = line.split(",")
vocab[int(line[index_pos])] = line[label_pos]
return vocab
def predict_json(instances, project=PROJECT, model=MODEL, version=None):
# To authenticate set the environment variable
# GOOGLE_APPLICATION_CREDENTIALS=<path_to_service_account_file>
service = googleapiclient.discovery.build("ml", "v1")
name = "projects/{}/models/{}".format(project, model)
if version is not None:
name += "/versions/{}".format(version)
response = service.projects().predict(
name=name,
body={"instances": instances}
).execute()
if "error" in response:
raise RuntimeError(response["error"])
return response["predictions"][0]
def parse_tfrecord(tfrec_file):
"""Encode tfrecord serialized string in base64."""
rec_iter = tf.io.tf_record_iterator(tfrec_file)
body = {"b64": base64.b64encode(next(rec_iter)).decode("utf-8")}
return body
def video_to_tfrecord(video_file):
video_tag = os.path.basename(video_file).split(".")[0]
tmpcsv, tmpcsv_name = tempfile.mkstemp()
tmprec, tmprec_name = tempfile.mkstemp()
with open(tmpcsv_name, "wt") as f:
f.write("{},0\n".format(video_file))
p = subprocess.Popen([
"python", FT_EXTRACTOR,
"--input_videos_csv", tmpcsv_name,
"--output_tfrecords_file", tmprec_name,
"--skip_frame_level_features", "false"
], stdout=sys.stdout)
out, err = p.communicate()
return tmprec_name
def download_yt(video_link, outdir=VIDEO_DIR):
"""Use youtube-dl to download a youtube video.
https://github.com/ytdl-org/youtube-dl
"""
video_tag = os.path.basename(video_link)
outfile = os.path.join(outdir, "{}.mp4".format(video_tag))
p = subprocess.Popen([
YT_DL, video_link,
"-o", outfile,
"-k",
"-f", "mp4"
], stdout=sys.stdout)
out, err = p.communicate()
return outfile
def inspect_tfrec(tfrec_file, is_sequence=False):
"""Print a tfrecord file content."""
record_iter = tf.io.tf_record_iterator(tfrec_file)
if is_sequence:
example = tf.train.SequenceExample()
example.ParseFromString(next(record_iter))
else:
example = tf.train.Example()
example.ParseFromString(next(record_iter))
return example
vocab = read_label_vocab()
@socketio.on("predict_request", namespace="")
def start_predict_pipeline(message):
# Form iframe to autoplay the requested youtube video.
video_link = message["link"]
video_tag = os.path.basename(video_link)
emit("video_response", {"tag": video_tag})
# Do prediction.
# Check if the video is already processed before.
tfrec_file = os.path.join(TFREC_DIR, "{}.tfrecord".format(video_tag))
if not os.path.exists(tfrec_file):
# Download the youtube video as mp4.
emit("status_update", {"status": "Start Downloading video..."})
video_file = download_yt(video_link)
if os.path.exists(video_file):
emit("status_update", {"status": "Download completed."})
else:
emit("status_update", {"status": "Invalid link!"})
return
# Convert mp4 to tfrecord.
emit("status_update", {"status": "Extracting video embeddings..."})
tmp_tfrec_file = video_to_tfrecord(video_file)
shutil.move(tmp_tfrec_file, tfrec_file)
emit("status_update", {"status": "Feature extraction completed."})
# Request online prediction service.
emit("status_update", {"status": "Request online predictions..."})
request_data = parse_tfrecord(tfrec_file)
responses = predict_json(request_data)
emit("status_update", {"status": "All done!"})
# Tidy predictions.
predictions = {}
proba = np.array(responses["activation"])
top_k_pos = proba.argsort()[-10:][::-1]
predictions["top_k"] = ["{}: {:.2%}".format(vocab[c], p) for c, p in
zip(top_k_pos, proba[top_k_pos])]
predictions["n_class"] = str((proba > .5).sum())
emit("predict_response", predictions)
@app.route("/", methods=["GET", "POST"])
def root():
return render_template("index.html")
if __name__ == "__main__":
# This is used when running locally only. When deploying to Google App
# Engine, a webserver process such as Gunicorn will serve the app. This
# can be configured by adding an `entrypoint` to app.yaml.
socketio.run(app,host="0.0.0.0", port=8080, debug=True)
Client-Side Coding¶
For the front-end we need to write some simple jquery to handle the asynchronous calls made by socket.io.
We will update the page right-hand sidebar on each background task to inform the user what's going on.
For a new video the processing time can easily exceed 1 minute which is definitely too long.
If there is no response at the page a user may feel frustrated and just go away.
The file app/templates/index.html is created as the following:
<!doctype html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>YouTube-8M-Demo</title>
<link rel="shortcut icon" href="{{ url_for('static', filename='favicon.ico') }}">
<link rel="stylesheet" href="{{ url_for('static', filename='style.css') }}">
<script src="{{ url_for('static', filename='jquery-3.4.1.min.js') }}"></script>
<script src="{{ url_for('static', filename='socket.io-2.2.0.min.js') }}"></script>
<script type="text/javascript" charset="utf-8">
// Handle async web socket communication.
$(document).ready(function() {
namespace = "";
var socket = io(namespace);
// Send async request to server.
$("form#yt_link").submit(function(event) {
socket.emit("predict_request", {link: $("#video_link").val()});
return false;
});
// Receive async response from server.
socket.on("video_response", function(msg, cb) {
var iframe = $("<iframe>", {
src: "https://www.youtube.com/embed/" + msg.tag + "?autoplay=1",
frameborder: 0,
style: "position:absolute;top:0;left:0;width:100%;height:100%;"
});
$("#video-frame").html(iframe);
// Clear previous predictions, if any.
$("#predictions").html("");
if (cb)
cb();
});
socket.on("predict_response", function(msg, cb) {
var output = $("<ol>");
output.append("<h2>Predictions</h2>")
var cnt = 0;
$(msg.top_k).each(function(index, item) {
cnt += 1;
output.append(
$(document.createElement("li")).text(item)
);
if ( cnt == msg.n_class ) {
output.append("---<br>")
}
});
output.append("---<br>")
output.append("Total No. of Predicted Classes: ")
output.append("<h2>" + msg.n_class + "</h2>")
$("#predictions").html(output);
if (cb)
cb();
});
socket.on("status_update", function(msg, cb) {
$("#predictions").append("<p>" + msg.status + "</p>");
if (cb)
cb();
});
});
</script>
</head>
<body>
<h1>Hello YouTube-8M!</h1>
<form id="yt_link" method="post" action="#">
<input placeholder="Put a youtube video link here..."
type="text" name="video_link" id="video_link"
style="width:45%;margin:auto;">
</form>
<section class="container">
<div class="left-half">
<div style="position:relative;padding-top:56.25%;">
<div id="video-frame"></div>
</div>
</div>
<div class="right-half">
<div id="predictions"></div>
</div>
</section>
</body>
Finally, this is how the app looks like after a prediction:
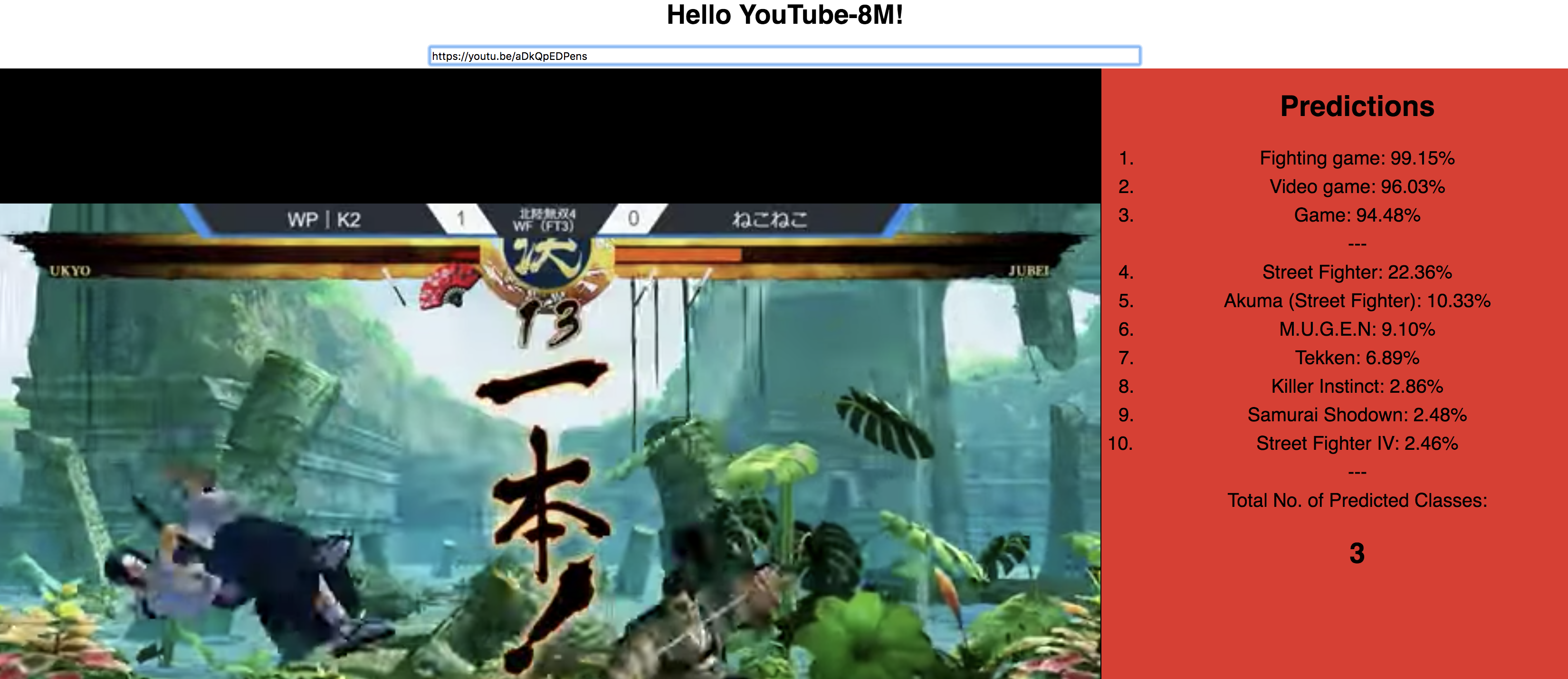
It can handle virtually any public YouTube video. Its a pity that the label Samurai Shodown didn't come at the top, since the game in play is indeed Samurai Shodown. But it is a brand-new released series title just a month ago as this writeup, so definitely we don't have any video about it in our training dataset.
Final Thoughts¶
TensorFlow is evolving very fast. There are a variety of ways in both training and deploying a machine learning model using TF. Currently there is really lacking a sort of developing best-practice in this field, due to the constant changing in its API design.
Some definitely directions to move forward, particularly for Keras integration:
- Better inter-operation between Keras model and TF estimator
- Right now the process is really buggy
- Better cloud prediction service deployment with Keras model
- A more unified (hence less confused) framework for model saving and prediction pipeline